Most of the recent breakthroughs in Artificial Intelligence are driven by data and computation. What is essentially missing is the energy cost. Most large AI networks require huge number of training data to ensure accuracy. However, these accuracy improvements depend on the availability of exceptionally large computational resources. The larger the computation resource, the more energy it consumes. This not only is costly financially (due to the cost of hardware, cloud compute, and electricity) but is also straining the environment, due to the carbon footprint required to fuel modern tensor processing hardware.
Considering the climate change repercussions we are facing on a daily basis, consensus is building on the need for AI research ethics to include a focus on minimizing and offsetting the carbon footprint of research. Researchers should also put energy cost in results of research papers alongside time, accuracy, etc.

The process of deep learning outsizing environmental impact was further highlighted in a recent research paper published by MIT researchers. In the "Energy and Policy Considerations for Deep Learning in NLP" paper, researchers performed a life cycle assessment for training several standard large AI models. They quantified the approximate financial and environmental costs of training various recently successful neural network models for NLP and provided recommendations to reduce costs and improve equity in NLP research and practice. They have also recommended reducing costs and improving equity in NLP research and practice.
"The compute costs are eye-watering"
Per the paper, training AI models can emit more than 626,000 pounds of carbon dioxide equivalent--nearly five times the lifetime emissions of the average American car (including the manufacture of the car itself). It is estimated that we must cut carbon emissions by half over the next decade to deter escalating rates of natural disasters.
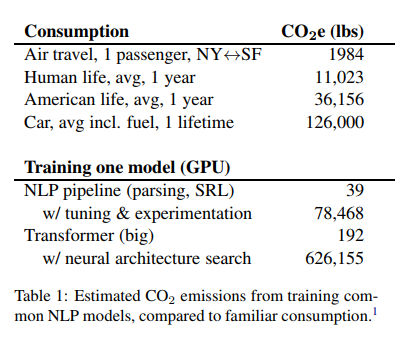
This speaks volumes about the carbon offset and brings the conversation to the returns on heavy (carbon) investment of deep learning and if it is worth the marginal improvement in predictive accuracy over cheaper, alternative methods. This news alarmed people tremendously.


In December, Sam Altman, CEO of ChatGPT, tweeted "the compute costs are eye-watering," which implies that the ChatGPT platform requires a lot of energy, and thus is responsible for a large amount of carbon emissions.
Even if some of this energy may come from renewable or carbon credit-offset resources, the high energy demands of these models are still a concern. This is because the current energy is derived from carbon-neural sources in many locations. Even when renewable energy is available, it is limited to the equipment produced to store it.
The carbon footprint of NLP models
The researchers in this paper adhere specifically to NLP models. First, they looked at four models, the Transformer, ELMo, BERT, and GPT-2, and trained each on a single GPU for up to a day to measure its power draw. Next, they used the number of training hours listed in the model's original papers to calculate the total energy consumed during the training process. This number was then converted into pounds of carbon dioxide equivalent based on the average energy mix in the US, which closely matches the energy mix used by Amazon's AWS, the largest cloud services provider.

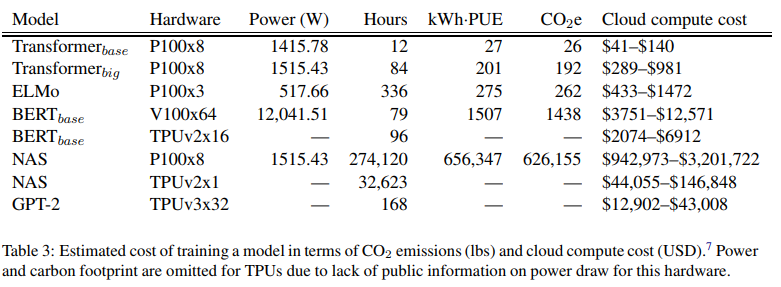
The researchers found that the environmental costs of training grew proportionally to model size. Furthermore, it exponentially increased when additional tuning steps increased the model's final accuracy. In particular, neural architecture search had high associated costs for little performance benefit. Neural architecture search is a tuning process that tries to optimize a model by incrementally tweaking a neural network's design through exhaustive trial and error. The researchers also noted that these figures should only be considered as a baseline. In practice, AI researchers mainly develop a new model from scratch or adapt an existing model to a new data set; both require many more rounds of training and tuning.
Based on their findings, the authors recommend specific proposals to heighten the awareness of this issue to the NLP community and promote mindful practice and policy:
- Researchers should report training time and sensitivity to hyperparameters.
There should be a standard, hardware-independent measurement of training time, such as gigaflops, required for convergence. There should also be a standard measurement of model sensitivity to data and hyperparameters, such as variance with respect to hyperparameters searched. - Academic researchers should get equitable access to computation resources.
This trend toward training huge models on tons of data is not feasible for academics because they don't have the computational resources. Instead, it will be more cost-effective for academic researchers to pool resources to build shared compute centers at the level of funding agencies, such as the U.S. National Science Foundation. - Researchers should prioritize computationally efficient hardware and algorithms.
For instance, developers could aid in reducing the energy associated with model tuning by providing easy-to-use APIs implementing more efficient alternatives to brute force.
The next step is to introduce energy costs as a standard metric, and researchers are expected to report their findings. They should also try to minimize carbon footprint by developing compute-efficient training methods such as new ML algos or new engineering tools to make existing ones more compute-efficient. Above all, we must formulate strict public policies that steer digital technologies toward speeding a clean energy transition while mitigating the risks.
Another factor contributing to high energy consumption is Optical neural networksused for most deep learning tasks. To tackle that issue, researchers and major tech companies -- including Google, IBM, and Tesla -- have developed "AI accelerators," specialized chips that improve the speed and efficiency of training and testing neural networks. However, these AI accelerators use electricity and have a theoretical minimum limit for energy consumption.
Also, most present-day ASICs are based on CMOS technology and suffer from the interconnect problem. Even in highly optimized architectures where data are stored in register files close to the logic units, most energy consumption comes from data movement, not logic. Analog crossbar arrays based on CMOS gates or memristors promise better performance, but analog electronic devices suffer from calibration issues and limited accuracy.
Implementing chips that use light instead of electricity
Another group of MIT researchers has developed a "photonic" chip that uses light instead of electricity and consumes relatively little power. The photonic accelerator uses more compact optical components and optical signal-processing techniques to drastically reduce power consumption and chip area.
Practical applications for such chips can also include reducing energy consumption in data centers.
"In response to vast increases in data storage and computational capacity in the last decade, the amount of energy used by data centers has doubled every four years and is expected to triple in the next ten years."

The chip could process massive neural networks millions of times more efficiently than today's classical computers.
How does the photonic chip work?
The researchers have explained the chip's working in their research paper, "Large-Scale Optical Neural Networks Based on Photoelectric Multiplication."
The chip relies on a compact, energy-efficient "optoelectronic" scheme that encodes data with optical signals but uses "balanced homodyne detection" for matrix multiplication. This technique produces a measurable electrical signal after calculating the product of the amplitudes (wave heights) of two optical signals.
Pulses of light encoded with information about the input and output neurons for each neural network layer — which are needed to train the network — flow through a single channel — optical signals carrying the neuron and weight data fan out to a grid of homodyne photodetectors. The photodetectors use the amplitude of the signals to compute an output value for each neuron. Each detector feeds an electrical output signal for each neuron into a modulator, which converts the signal back into a light pulse. That optical signal becomes the input for the next layer, and so on.
Limitation of Photonic accelerators
Photonic accelerators generally have an unavoidable noise in the signal — the more light fed into the chip, the less noise and accuracy. Less input light increases efficiency but negatively impacts the neural network's performance. The ideal condition is achieved when AI accelerators are measured in how many joules it takes to perform a single operation of multiplying two numbers. Traditional accelerators are measured in picojoules or one-trillionth of a joule. Photonic accelerators measure in attojoules, which is a million times more efficient. In their simulations, the researchers found their photonic accelerator could operate with sub-attojoule efficiency.
Tech companies are the most significant contributors to the carbon footprint
The realization that training an AI model can produce emissions equivalent to five cars should make the carbon footprint of artificial intelligence an essential consideration for researchers and companies going forward.
UMass Amherst's Emma Strubell, one of the research team and co-author of the paper, said, "I'm not against energy use in the name of advancing science, obviously, but I think we could do better in terms of considering the trade-off between required energy and resulting model improvement."
"I think large tech companies that use AI throughout their products are likely the largest contributors to this energy use," Strubell said. "I do think that they are increasingly aware of these issues, and there are also financial incentives for them to curb energy use."
In 2016, Google's 'DeepMind' reduced the energy required to cool Google Data Centers by 30%. This full-fledged AI system has features including continuous monitoring and human override.
Recently Microsoft doubled its internal carbon fee to $15 per metric ton on all carbon emissions. The funds from this higher fee will maintain Microsoft's carbon neutrality and help meet its sustainability goals. On the other hand, Microsoft is also two years into a seven-year deal--rumored to be worth over a billion dollars--to help Chevron, one of the world's largest oil companies, better extract and distribute oil.
Amazon had announced that it would power data centers with 100 percent renewable energy without a dedicated timeline. However, since 2018 Amazon has reportedly slowed down its efforts to use renewable energy using only 50 percent. It has also not announced any new deals to supply clean energy to its data centers since 2016, according to a report by Greenpeace, and it quietly abandoned plans for one of its last scheduled wind farms last year. In April, over 4,520 Amazon employees organized against Amazon's continued profiting from climate devastation. However, Amazon rejected all 11 shareholder proposals, including the employee-led climate resolution, at the Annual shareholder meeting.
Both these studies' researchers illustrate the dire need to change our outlook toward building Artificial Intelligence models and chips that impact the carbon footprint. However, this does not mean halting the research of AI altogether. Instead, there should be an awareness of the environmental impact of training AI models. This can inspire researchers to develop more efficient hardware and algorithms for the future.
Packt is a Learning Tree thought leadership content partner. For more AI content, visit the Packt Hub >
Visit Learning Tree for AI training opportunities:
Introduction to AI, Data Science & Machine Learning with Python
This piece was originally posted July 31, 2019 and has been reposted with refreshed information, styling, and headers.