You probably thought that the chapter on binary number systems in your Intro to Computer Science textbook would never have to be opened again, especially now that you're a report writer or a data analyst and generally don't get too close to the silicon. SQL Server DBAs bump into binary numbers from time to time when using some administrative and monitoring functions. But even analysts may have to deal with them when writing some queries that involve aggregation and grouping.
CUBE and ROLLUP
According to the strict rules, query results should contain detail data or aggregate data, but not both. CUBE and ROLLUP violate the strict rules by not only mixing details with aggregated values, but also by included values aggregated at different levels.
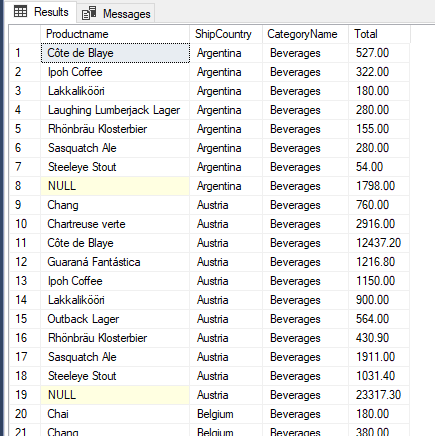
In this example, the NULL at row 8 indicates the row value for Argentina is aggregated over all beverages; the NULL at row 19 represents the beverage aggregation for Austria.
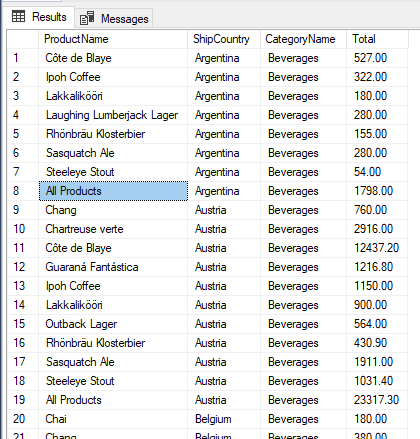
Clearly "NULL" is hardly acceptable for a report to be viewed by anyone other than a hard-core analyst.. Even to this day, the classic GROUPING( ) function is the simplest and most practical means to solve this problem. GROUPING(columnName) will return 1 if that particular row represents a grouping on the "columnName" column. In the following example we use GROUPING( ) to improve the readability of the results.
SELECT CASE GROUPING(Productname)
WHEN 1 THEN 'All Products'
ELSE Productname
END AS ProductName
,CASE GROUPING(ShipCountry)
WHEN 1 THEN 'All Countries'
ELSE ShipCountry
END AS ShipCountry
,CASE GROUPING(CategoryName)
WHEN 1 THEN 'All Categories'
ELSE CategoryName
END AS CategoryName
,SUM(CAST(od.UnitPrice * od.Quantity * (1- od.Discount)AS MONEY)) AS Total
FROM [Order Details] od
JOIN Products p
ON p.ProductID = od.ProductID
Join Orders o
ON od.OrderID = o.OrderID
JOIN Categories c
ON p.CategoryID = c.CategoryID
GROUP BY CUBE(ProductName, ShipCountry, CategoryName)
GROUPING_ID( )
The GROUPING_ID( ) function provides an alternative for managing group labels in the output. In the following example, a new column is created to provide a description of which column or combination of columns is being grouped for any particular output row.
SELECT CASE GROUPING_ID(ProductName, ShipCountry, CategoryName)
WHEN 1 THEN 'Categories'
WHEN 2 THEN 'ShipCountries'
WHEN 3 THEN 'Categories, ShipCountries'
WHEN 4 THEN 'Products'
WHEN 5 THEN 'Products, Categories'
WHEN 6 THEN 'Products, ShipCountries'
WHEN 7 THEN 'Products, ShipCountries, Categories'
END
AS GroupingLevel
,Productname
,ShipCountry
,CategoryName
,SUM(CAST(od.UnitPrice * od.Quantity * (1- od.Discount)AS MONEY)) AS Total
FROM [Order Details] od
JOIN Products p
ON p.ProductID = od.ProductID
Join Orders o
ON od.OrderID = o.OrderID
JOIN Categories c
ON p.CategoryID = c.CategoryID
GROUP BY CUBE(ProductName, ShipCountry, CategoryName)
img src="https://cdn.buttercms.com/LeHRbdIXSL6EBIxUyjO0" />
This is all very well and good, but where did the 1, 2, 3, ..., 7 come from in the CASE statement in the query? This is where the binary comes into play.
If we call GROUPING_ID with a single column argument, the results are indistinguishable from those of GROUPING. However, if we invoke GROUPING_ID with a set of column names as an argument, each column name becomes associated with a single bit in the output. For example, in the above query we used
GROUPING(ProductName, ShipCountry, CategoryName)
The output will be a single integer, but let's consider it as a row of bits.
ProductName |
ShipCountry |
CategoryName |
||
24 |
23 |
22 |
21 |
20 |
16 |
8 |
4 |
2 |
1 |
The least-order bit is associated with the last column in the list, the second-least order bit is associated with the second-to-last column and so forth. Note that bits are determined by the argument list to the GROUPING_ID function and have nothing to do with the sequence of column names in the GROUP BY or CUBE function.
In this example, if a row represented a grouping on only ProductName, then the value in the ProductName "column" would be 1, representing a bit in the "4s" column. Since ShipCountry and CategoryName are zero, the total for the GROUPING_ID output would be 4.
ProductName |
ShipCountry |
CategoryName |
||
24 |
23 |
22 |
21 |
20 |
16 |
8 |
4 |
2 |
1 |
0 |
0 |
1 |
0 |
0 |
Similarly, if the row represented an grouping on ProductName and ShipCountry, but not on CategoryName, there would be a "1" bit in the 4s and the 2s column.
ProductName |
ShipCountry |
CategoryName |
||
24 |
23 |
22 |
21 |
20 |
16 |
8 |
4 |
2 |
1 |
0 |
0 |
1 |
1 |
0 |
The total value for the output integer in this case would be 6.
Conclusion
In all likelihood, the GROUPING( ) function will continue to serve most of your needs for queries using CUBE and ROLLUP. However, if you need more flexibility, GROUPING_ID is easy to use once you see how the values for the integer output are calculated and interpreted.
Related Training:
Developing SQL Queries for Oracle Databases
Advanced SQL Course
SQL Server Training
