The tabular mode data storage used by Power BI, Power Pivot, and the SQL Server Analysis Services thrives on sufficient memory. Take away memory and performance plummets. You may be wasting memory and thus performance if you do not take advantage of opportunities to trim excess fat when you are first importing your data. And, if you do not consider tabular mode compression algorithms, you may be overlooking opportunities.
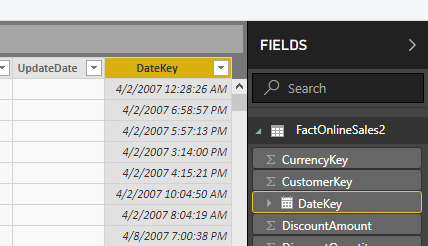
We will use Microsoft's ContosoRetailDW database for our example, because the FactOnlineSales table has over 12 million rows, large enough to explore the effects of data compression. We will, however, make one modification. The DateKey column in Microsoft's example does not contain any time information, that is, all the times are midnight. To emulate real-world data, in which we might find times other than midnight, I have artificially altered the DateKey column to include random time values other than midnight. (Note that we are not intending to use this column in its role as a key column; we are just going to look at the effects of compression.)
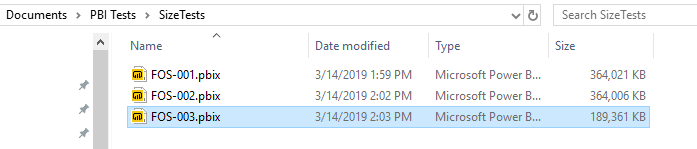
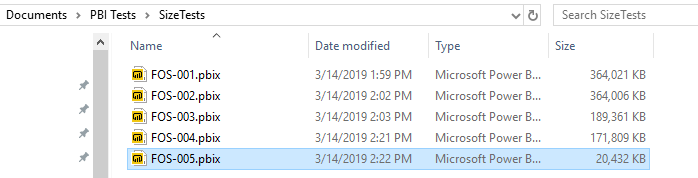
Saving the pbix file containing the FactOnlineSales table we see the file size is 364,021 KB.
Like many data warehouse fact tables, FactOnlineSales contains columns with administrative information labelled ETLLoadID, LoadDate, UpdateDate that are of no value to any analyst using PowerBI. Of course, we will remove those columns. When we completely remove these columns and save again, the results are a little disappointing.
We have saved only 15 kilobytes. This is to be expected, however. Since the administrative columns contain highly repetitive values, Power BI's xVelocity engine can compress them greatly. Such highly repetitive columns do not contribute much to the overall data volume. What we would like is to remove columns with many distinct values, since such columns do not compress nearly as effectively. One example in the FactOnlineSales table is the SalesKey. You might be uncomfortable removing a column with "Key" in its name, but if none of the dimension tables refer to it and none of the analysts want it, then out it should go.
This time the saving are almost 75 MB, far more satisfying. Let's see how much better we can do.
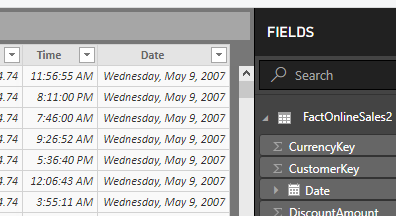
The DateKey column has a great many distinct values, but most of these distinct values are a result of the time portion. The number of distinct dates is far smaller. Let's try splitting the DateKey column into a Date column and a Time column.
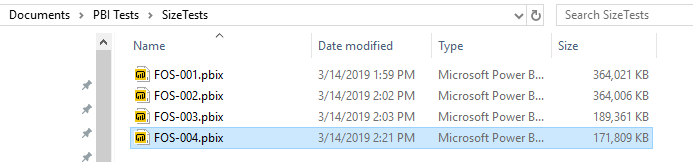
When we save, we see that over 17 MB have been saved. This might seem counterintuitive. We have split a single column into two. We have removed no data whatsoever, but we have saved 17 MB. The reason this works is that after we have split the DateKey column the new Date column has many repetitive values and therefore compresses well.
We could save even more by removing the time column, and we shall do that momentarily. But what if we needed time information? Well, you might not need time down to the second. Indeed, the nearest hour might suffice for analytical purposes. By rounding time to the nearest hour, we could reduce the number of distinct values in the column to a mere 24, once again achieving great savings. But now, for simplicity's sake, we will just remove the time column and see what happens.
As was the case with the removal of the SalesKey column, removing the large number of distinct values in the Time column resulted in substantial savings.


Conclusion
Careful trimming of unnecessary data in a Power BI database can result in a considerable reduction in space requirements. This example was artificial in that we were working with only a single fact table, but the results are clear. In this example, a roughly 364 MB xVelocity database was reduced to under 21 MB.
